Solutii Algoritmiada 2019 Runda Finala
Solutia problemei Anagrame2
Multumim lui 
- Voi utiliza si cod in limbajul c++ pentru a usura intelegere solutiei
| Capitol 1 : | interactiunea |
|---|
Cum realizam interactiunea?
Vom scrie o functie "ask" care ne va usura procesul de interactiune :
string ask(string s) {
cout << s << endl;
cin >> s;
return s;
}(daca folosim "<< endl", se realizeaza flush automat si nu mai este nevoie sa facem flush manual)
| Capitol 2 : | transformare din numar in caracter |
|---|
char getch(int i) {
if (i <= 9)
return (char) (i + '0');
else
return (char) (i - 10 + 'a');
}| Capitol 3 : | Caz particular in care numarul este 0 |
|---|
daca nu avem alte cifre in afara de 0 => numarul nostru este chiar 0
if (f[0] == len) {
ask("0");
continue;
}| Capitol 4 : | solutia de 23 de puncte |
|---|
- Pentru 23 de puncte, trebuie sa punem mai putin de 900 de intrebari.
- Notam cu b = baza numarului
- Notam cu len = f [0] + f [1] + ... + f [b - 1], len este lungimea numarului in baza b
- din enunt avem 1 <= len, b <= 30
- avem 30 * 30 = 900, de aici ne putem sa ne gandim ca avem nevoie de o solutie care pune len * b intrebari
- ne gandim sa parcurgem cifrele numarului de la stanga la dreapta (de la cea mai semnificativa la cea mai nesemnificativa) si sa aflam cifrele numarului ascuns in aceasta ordine
- presupunem ca stim deja primele k cifre ale numarului, ele fiind de forma X1, X2, ..., XK, ?, ?, ?, ..., ?, ? (ultimele len - k cifre sunt inca necunoscute)
- verificam ce cifra am putea sa punem, pornind de la cea mai mica posibila la cea mai mare (ex: cif = 0, 1, 2, ..., b - 1)
- vrem sa verificam daca x[K+1] = cif
- avem Q = x [1], x [2], ..., x[k+1], ?, ?, ?, ..., ? inlocuim cifrele "necunoscute" astfel incat sa formam cel mai mare numar posibil care sa fie anagrama a numarului nostru
string build_max_string(string cur) { // cur = x[1], x[2], ..., x[k+1]
for (int j = b - 1; j >= 0; j--)
for (int i = 0; i < f[j]; i++)
cur += getch(j);
return cur;
}11. intrebam ask(numarul Q) si notam O = ask(numarul Q)
12. daca O = "<" => numarul maxim pe care il putem obtine este mai mic decat numarul necunoscut => trecem mai departe si verificam daca x[k+1] poate sa fie cif+1
13. daca O = "=" => numarul Q este numarul necunoscut => trecem imediat la urmatorul test
14. daca O = ">" => numarul maxim pe care il putem obtine este mai mare decat numarul necunoscut => x[k+1] este cif => trecem mai departe sa calculam x[k+2]
bool ok = 0;
string cur;
for (int step = 1; step <= len && !ok; step++) {
for (int i = (step == 1); i < b; i++) {
if (f[i] > 0) {
f[i]--;
string curi = cur + getch(i), mxposi = build_max_string(curi);
string s = ask(mxposi);
if (s == "=") { /// pasul 13
ok = 1;
break;
}
if (s == ">") { /// pasul 14
cur = curi;
break;
}
f[i]++; /// pasul 12
}
}
}| Capitol 5 : | solutia de 100 de puncte |
|---|
- se garanteaza ca sunt cel mult 258 numere distincte care se pot forma cu frecventele din input
- de aici, vine si ideea de a folosi cautarea binara
- ca sa calculam numarul total de anagrame o sa folosim formula combinarilor cu repetitii : k = len! / (f [0]! * f [1]! * ... * f[b-1]!)
- trebuie sa avem grija sa NU numaram si "anagramele" care incep cu 0, numarul acestora fiind zero = k / len * f [0]
- vom lucra pe numere de tip long long pe indici, atribuind fiecarui numar natural de la 1 la k o anagrama a numarului din input
- astfel fiecarei anagrame i se atribuie o valoare x
- in exemplu, testul 1 :
- k = 6 si zero = 2
- anagrama 1 : 012
- anagrama 2 : 021
- anagrama 3 : 102
- anagrama 4 : 120
- anagrama 5 : 201
- anagrama 6 : 210
- deoarece anagrama secreta NU poate incepe cu 0 => valoarea anagramei noastre este [zero + 1, zero + 2, ..., zero + k]
- acum ne trebuie o functie care construieste a x-a anagrama a numarului din input
- vom lua la rand pozitiile de la 1 la len si ca la solutia de 23 de puncte o sa construim secvential solutia
- mentinem o variabila aux care ne spune cate anagrame au ca prefix sirul nostru de pana acum, initial aux = k, sirul nostru fiind vid si toate sirurile avand ca prefix sirul vid
- presupunem ca am aflat primele k pozitii si vrem sa o aflam pe a k + 1 - a pozitie; parcurgem toate caracterele posibile si vedem daca numarul de anagrame care au prefix-ul mai mic sau egal decat cele k + 1 pozitii depaseste variabila noastra x
string gen(ll x) {
for (int j = 0; j < n; j++)
a[j] = f[j];
string s;
ll aux = k;
for (int i = 1; i <= len; i++) {
ll sum = 0;
for (int j = 0; j < n; j++) {
ll t = aux * a[j] / (len - i + 1);
sum += t;
if (sum >= x) {
s += getch(j);
a[j]--;
aux = t;
x -= (sum - t);
break;
}
}
}
return s;
}10. trebuie sa calculam k si zero
11. deoarece 30! este prea mare si nu intra pe long long, dar rezultatul va intra pe long long, vom retine exponentii fiecarui numar prim <= 30; amintim ca : k = len! / (f [0]! * f [1]! * ... * f[b-1]!)
memset(exp, 0, sizeof exp);
for (int i = 2; i <= len; i++) {
int cop = i;
for (int j = 2; j <= cop; j++)
while (cop % j == 0)
cop /= j, exp[j]++;
}
for (int i = 0; i < n; i++)
for (int k = 2; k <= f[i]; k++) {
int cop = k;
for (int j = 2; j <= cop; j++)
while (cop % j == 0)
cop /= j, exp[j]--;
}
k = 1;
for (int i = 1; i <= len; i++)
for (int j = 1; j <= exp[i]; j++)
k *= i;
zero = all * f[0] / len;12. ultimul pas : cautarea binara
ATENTIE trebuie inceputa de la zero + 1 ca limita inferioara si k ca limita superioara pentru a NU lua in considerare numerele care incep cu 0!!!
ll lo = zero + 1, hi = all;
while (lo <= hi) {
ll mid = (lo + hi) / 2;
string ch = ask(gen(mid));
if (ch == "=")
break;
if (ch == "<")
lo = mid + 1;
else
hi = mid - 1;
}Solutia problemei Silvania
Multumim lui 
Initial, vom folosi 2 vectori:
- lemn[x] - cat lemn are copacul de pe pozitia x in vectorul initial
- poz[x] - pe ce pozitie in padure se afla copacul de pe pozitia x in vectorul initial
Vom sorta copacii dupa pozitia lor in vectorul poz. Acest lucru poate fi facut utilizand un vector de structuri sau de pair.
Solutie N3 * log(N) - ~20 puncte
Vom fixa 2 indici, i si j, (i ≤ j) si vom itera cu i de la 1 la n, iar cu j de la i la n. In acest moment presupunem ca am taiat toti copacii de la stanga lui i si de la dreapta lui j.
Deci lemnul total este lt = ![\displaystyle \sum_{x=1}^{i-1} lemn[x] + \sum_{y = j + 1}^{n} lemn[y]](http://www.infoarena.ro/static/images/latex/1d392a67e9ab827b172ddf26e1617f78_15.15974pt.gif "\displaystyle \sum_{x=1}^{i-1} lemn[x] + \sum_{y = j + 1}^{n} lemn[y]") .
.
Distanta este dist = poz[j] - poz[i]. Daca dist > lt, atunci vom taia copacii care au cel mai mult lemn cat timp dist > lt. Acest lucru poate fi facut sortand intervalul [i,j] si luand elementele maxime.
Solutie N3 - ~20 puncte
Se va proceda la fel ca anterior, insa se vor face 2 observatii:
- Daca un copac este taiat, atunci el va ramane taiat pana ce capatul stanga va ajunge la urmatoarea pozitie;
- La fiecare pas, vectorul lemn va avea deja elementele in ordine crescatoare. De aceea putem insera elementul curent in complexitate O(N) si nu va fi necesar sa sortam vectorul din nou.
Solutie N2 * log(N) - 100 puncte
Se va proceda la fel ca la solutia precedenta, insa se va folosi o structura de date numita heap . Aceasta structura de date ne va permite sa inseram si sa stergem elementul curent in complexitate O(log(N)).
Solutie N2 - 100 puncte
Vom fixa numarul de lemne maxim lmax pe care il putem lua de la un copac, iterand cu el de la 1 la n. Apoi, pentru fiecare maxim fixat, vom folosi tehnica 2-pointers. Vom folosi din nou 2 indici, i si j, (i ≤ j), care la inceput vor fi amandoi 1. Astfel, daca lemn[j] ≤ lmax, atunci vom taia copacul j. Daca, la un moment dat, distanta dintre poz[i] si poz[j] este mai mare decat lemnul curent, vom creste capatul stanga. Complexitatea tehnicii 2-pointers este O(N), ceea ce garanteaza complexitatea finala de O(N2), care va lua punctaj maxim.
OBSERVATIE: lmax nu poate fi cautat binar.
Solutia problemei Aliniate
Multumim lui 
Solutie O(1) - subtask 5 puncte
Avem conditia ca intervalele nu se intersecteaza ne garanteaza ca vom putea mereu satisface cerintele respectivelor intervale.
O metoda de a construi solutia este de a pune pe o pozitie dintr-un interval valoarea ceruta de acesta si pe restul pozitiilor ramase valoarea 1.
Solutie O(N*log(N)) - subtask 30 puncte
Datorita conditiei de "aliniere" si a faptului ca toate numerele din input sunt impare, deducem ca intervalele pot avea doar lungimea 1.
Daca ar avea o lungime mai mare de 1 si ar fi si o putere de 2, am avea cel putin un capat cu o valoare para, deci contradictie.
Tot ce ne mai ramane sa verificam acum este daca se contrazic doua restrictii din datele de la intrare direct una cu alta.
Putem salva intervalele unitate intr-o structura de date de tip map din stl pentru verificare.
Solutie O(N*log(N)) - 100 puncte
Vom avea nevoie de cateva observatii:
- Putem verifica o structura de tip map din stl daca doua intervale din input se contrazic direct.
- Intervalele aliniate formeaza de fapt un arbore binar perfect si/sau complet (Toate nodurile mai putin frunzele au exact 2 fii). Vom asocia astfel fiecarui nod din arbore un interval din input, astfel incat radacina reprezinta intervalul
![\interval[{0,2^{30}-1}]](http://www.infoarena.ro/static/images/latex/346af4f8c55db9092f6ef08088860608_3.5pt.gif "\interval[{0,2^{30}-1}]")
- Daca ignoram puterile de 2 intr-un numar, putem cu un singur numar sa trecem de la orice x la alt y datorita teoremei euler.
Cum nu putem tine in memorie intreg arborele va trebui sa construim doar nodurile care ne intereseaza. Observam ca ne intereseaza doar nodurile date de setul format din intervalele date si toti stramosii lor. O sa avem astfel maxim N*log(N) noduri.
Putem calcula o dinamica in fiecare nod care sa ne spuna daca putem sau nu construi acest nod.
Pentru fiecare nod o sa avem nevoie de urmatoarele:
- Pentru fiecare nod, vom avea nevoie sa stim daca avem cel putin un element "nefixat", adica daca putem folosi un element din acest interval pentru a satisface o restrictie in unul din stramosi, daca este cazul.
- Puterea de 2 "ceruta" de acest interval. Deoarece lucram modulo
 o data ce apare un 2 ca factor, nu mai putem scapa de el, mai rau, o data ce avem un 0, orice stramos va avea valoarea 0
o data ce apare un 2 ca factor, nu mai putem scapa de el, mai rau, o data ce avem un 0, orice stramos va avea valoarea 0 - Ignorand puterile de 2, ne intereseaza ce restrictie avem pentru acest nod. (Produsul format din elementele ei)
Impreuna cu a 2-a observatie de mai sus, putem memora un singur numar pentru restrictia valorii produsului unui interval.
Intr-o maniera DFS, vom calcula aceasta dinamica, avand diferite cazuri.
Frunzele sunt initializate cu valorile din input si vor fi marcate ca "pline", adica nu mai putem modifica niciun element din ele.
Pentru un nod, avem 2 cazuri principale:
- nu avem restrictie data in input pentru interval. Avem de calculat doar produsul restrictiilor celor 2 fii. Pentru fii inexistenti putem presupune ca avem numai valori de 1, dar atentie, putem modifica aceste valori pentru restrictii cerute de eventualii stramosi.
- avem o restrictie pentru nod. In primul rand trebuie sa verificam daca fii cer in total o putere de 2 mai mare decat restrictia noastra din nod (Daca da, nu avem solutie). Daca avem cel putin un fiu lipsa, putem folosi un element din celalalt fiu pentru a ne rezolva restrictia din nodul dat, nod. Daca in schimb ambii fii au restricti si sunt si marcati ca plini, atunci verificam ca produsul restrictiilor fiilor sa corespunda cu restrictia din nod.
Pentru a implementa elegant structura de arbore, vom construi dupa citirea intervalelor un nod radacina, si apoi, pentru fiecare interval vom construi "un path" pana la nodul asociat intervalului. Este asemanator ca adaugarea unui sir de caractere intr-o trie.
Detalii de implementare si alte trucuri se gasesc la sursa Submisie
Solutia problemei Djok
Multumim lui 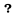
Solutie ") - 30p
- 30p
Sa zicem ca Tanaka alege sa controleze monstruletul din nodul i. Atunci o strategie optima pentru el este sa atace tot timpul cel mai slab monstrulet din nodurile nevizitate in care poate ajunge. Strategia aceasta este optima pentru ca fie Tanaka poate bate monstruletul, caz in care vitejia monstrului controlat fie creste fie ramane la fel, fie nu il poate bate, dar atunci el nu va putea bate niciun alt monstrulet la care are acces. Asadar problema ne cere ca, pentru o multime de noduri vizitate, sa gasim nodul adiacent unuia dintre nodurile deja vizitate, care contine monstruletul cu cea mai mica vitejie. Asadar, pentru un nod de inceput i fixat, putem sa il bagam intr-un heap. Acum vom face un algoritm asemanator celui de BFS/Dijkstra, si vom tot extrage din heap nodul cu cel mai mic cost, vom verifica daca putem bate monstruletul din nodul acela, si daca da il scoatem si ii adaugam in heap vecinii nevizitati, si eventual actualizam vitejia monstruletului nostru.
Solutie ") - 100p
- 100p
Fie  vitejia monstruletului din nodul i.
vitejia monstruletului din nodul i.
Fie  multimea nodurilor la care poti ajunge din i si pe care le poti bate cu monstruletul din nodul i fara a iti schimba vitejia.
multimea nodurilor la care poti ajunge din i si pe care le poti bate cu monstruletul din nodul i fara a iti schimba vitejia.
Atunci va fi multimea conexa de noduri cu valori pana in  , care il contine pe i.
, care il contine pe i.
Se poate observa ca daca in multimea asta exista un nod j, cu vitejia mai mare decat i, atunci  . De ce?
. De ce?
Deoarece j se afla in , inseamna ca pe lantul de i la j toti monstruletii au vitejia mai mica sau egala cu  , si cum
, si cum  , sigur putem ajunge si din nodul j in nodul i, si deci acum e ca si cum am porni cu un monstrulet cu vitejia
, sigur putem ajunge si din nodul j in nodul i, si deci acum e ca si cum am porni cu un monstrulet cu vitejia  din nodul i, ceea ce e mai bine. Deoarece
din nodul i, ceea ce e mai bine. Deoarece  , inseamna ca putem sa batem monstruletul j, deci putem creste vitejia monstruletului nostru la . Asadar, raspunsul pentru nodul i va fi acelasi cu raspunsul pentru nodul j.
, inseamna ca putem sa batem monstruletul j, deci putem creste vitejia monstruletului nostru la . Asadar, raspunsul pentru nodul i va fi acelasi cu raspunsul pentru nodul j.
Acum ce mai ramane de vazut e cum gasim pentru un nod i, un nod j cu cu . Pentru asta vom pune intrebarea invers: un nod i, pentru ce alte noduri este nodul cautat? Hai sa sortam nodurile crescator dupa . Cum am mentionat anterior, toate sunt multimi conexe de noduri, si asta ne-ar putea face sa ne gandim la paduri de multimi disjuncte. Hai sa inseram nodurile arborelui crescator dupa valoare. Sa zicem ca am inserat primele i - 1 noduri,si acum suntem la al i-lea. Vom creea o noua multime pentru nodul nod inserat si vom uni cu aceasta toate multimile care contin un nod vecin al nodului nou inserat. Nodul curent va putea fi nodul cautat doar pentru nodurile cu vitejie maxima din aceste multimi. De ce? Pentru ca orice alt nod din ele au avut deja oportunitatea de a se lega de nodul cu vitejie maxima din multimea lor, deci daca nu au facut-o e pentru ca au vitejia prea mica pentru acesta. Asadar, la unirea unei multimi cu noua multime a nodului al i-lea, vom verifica daca nu cumva nodul cu vitejia maxima din ele nu poate sa se lege de nodul curent.
Acum stim pentru fiecare nod i, fie stim un nod j care are acelasi raspuns, fie un nod de genul nu exista, ceea ce ar inseamna ca monstruletul din nodul i nu isi va schimba niciodata vitejia, si asadar va bate doar noduri la care poate ajunge fara sa isi schimbe vitejia, adica . O ultima observatie ne ajuta sa finalizam problema: multimea este egala cu multimea care contine nodul i, de la momentul in care in structura de paduri de multimi disjuncte de la pasul anterior l-am inserat pe i. Asadar, putem tine minte aceasta dimensiune, iar la final pentru a afla raspunsul pentru i sa folosim o structura asemanatoare multimiilor de paduri disjuncte.
O solutie bazata pe aceasta idee se gaseste aici
Solutia problemei Bisuma
Multumim lui 
Solutie O(N2 * K) - 30 de puncte
Vom rezolva aceasta problema folosind programarea dinamica. Fie dinamica:
![dp[K][N] = \mbox{valoarea minima a impartirii daca as folosi K bucati folosind primii N copii}](http://www.infoarena.ro/static/images/latex/5b276c921cc829e5946a3b241a7c32a6_3.5pt.gif "dp[K][N] = \mbox{valoarea minima a impartirii daca as folosi K bucati folosind primii N copii}")
Formula de recurenta este urmatoarea:
![dp[K][N] = min(dp[K][T] + max(a[T + 1] + a[T + 2] + ... + a[N], b[T + 1] + b[T + 2] + ... + b[N]))](http://www.infoarena.ro/static/images/latex/9c6ba0f24b4c23fa6fc5cebc74d8d865_3.5pt.gif "dp[K][N] = min(dp[K][T] + max(a[T + 1] + a[T + 2] + ... + a[N], b[T + 1] + b[T + 2] + ... + b[N]))")
Pentru a simplifica formula, vom folosi sume partiale: sa[N] = a[1] + a[2] + ... + a[N] si sb[N] = b[1] + b[2] + ... + b[N] . Astfel formula va deveni:
![dp[K][N] = min(dp[K - 1][T] + max(sa[N] - sa[T], sb[N] - sb[T]))](http://www.infoarena.ro/static/images/latex/e4861862c1570694b9a048abc1039d26_3.5pt.gif "dp[K][N] = min(dp[K - 1][T] + max(sa[N] - sa[T], sb[N] - sb[T]))")
Formula de recurenta are complexitatea O(N), astfel complexitatea finala va deveni O(N2 * K).
Solutie O(N * K * logN) - 100 de puncte
Pentru a rezolva problema, trebuie sa analizam si mai mult formula de recurenta. Pentru inceput, vom explicita functia de maxim din interior:
![dp[K][N] = min \begin{cases} dp[K - 1][T] + sa[N] - sa[T], & \mbox{daca } sa[N] - sa[T] >= sb[N] - sb[T] \ dp[K - 1][T] + sb[N] - sb[T], & \mbox{in caz contrar contrar} \end{cases}](http://www.infoarena.ro/static/images/latex/bc8f54396b3cb410f62a317dfbec950d_13.50015pt.gif "dp[K][N] = min \begin{cases} dp[K - 1][T] + sa[N] - sa[T], & \mbox{daca } sa[N] - sa[T] >= sb[N] - sb[T] \ dp[K - 1][T] + sb[N] - sb[T], & \mbox{in caz contrar contrar} \end{cases}")
Rescriind conditia pentru primul caz, obtinem
![dp[K][N] = min \begin{cases} dp[K - 1][T] + sa[N] - sa[T], & \mbox{daca } sa[N] - sb[N] >= sa[T] - sb[T] \ dp[K - 1][T] + sb[N] - sb[T], & \mbox{in caz contrar contrar} \end{cases}](http://www.infoarena.ro/static/images/latex/04d2fd9a71f73526b31515e8fc68d4e5_13.50015pt.gif "dp[K][N] = min \begin{cases} dp[K - 1][T] + sa[N] - sa[T], & \mbox{daca } sa[N] - sb[N] >= sa[T] - sb[T] \ dp[K - 1][T] + sb[N] - sb[T], & \mbox{in caz contrar contrar} \end{cases}")
Grupand termenii, mutandu-i in fata, obtinem
![dp[K][N] = min \begin{cases} sa[N] + min(dp[K - 1][T] - sa[T]), & \mbox{daca } sa[N] - sb[N] >= sa[T] - sb[T] \ sb[N] + min(dp[K - 1][T] - sb[T]), & \mbox{in caz contrar contrar} \end{cases}](http://www.infoarena.ro/static/images/latex/01a0373cf95db4a5ef0b415511761df1_13.50015pt.gif "dp[K][N] = min \begin{cases} sa[N] + min(dp[K - 1][T] - sa[T]), & \mbox{daca } sa[N] - sb[N] >= sa[T] - sb[T] \ sb[N] + min(dp[K - 1][T] - sb[T]), & \mbox{in caz contrar contrar} \end{cases}")
Pentru a calcula dinamica, vom folosi doi vectori auxiliari initializati cu infinit pe toate pozitiile, fie acestia besta si bestb. Cand calculam dp[K][N], vrem ca besta[x] = min(dp[K][T] - sa[T] unde T < N si sa[T] - sb[T] == x), analog pentru bestb. Astfel, formula va deveni:
![dp[K][N] = min \begin{cases} sa[N] + min(besta[T] \mbox{ pentru } T <= sa[N] - sb[N]) \ sb[N] + min(bestb[T] \mbox{ pentru } T >= sa[N] - sb[N])\end{cases}](http://www.infoarena.ro/static/images/latex/9b93f2f3aa8af99b3a6ce2a5ebd42961_13.50015pt.gif "dp[K][N] = min \begin{cases} sa[N] + min(besta[T] \mbox{ pentru } T <= sa[N] - sb[N]) \ sb[N] + min(bestb[T] \mbox{ pentru } T >= sa[N] - sb[N])\end{cases}")
Aceasta structura de date este ineficienta, deoarece, desi update-ul se face in O(1), query-ul se face in complexitate O(VAL_MAX). Pentru a optimiza aceasta structura, putem folosi una din urmatoarele structuri:
- un arbore de intervale in care normalizam coordonatele sa[T] - sb[T] cu O(logN) per update sau query
- un arbore indexat binar in care normalizam coordonatele sa[T] - sb[T] cu O(logN) per update sau query
- un set in care atunci cand inseram o pereche {sa[N] - sb[N], dp[K][N] - sa[N]}, eliminam toate perechile {x, y} cu sa[N] - sb[N] ≥ x si dp[K][N] - sa[N] ≤ y cu O(logN) per update sau query
- un arbore binar echilibrat cu O(logN) per update sau query
- un arbore de intervale alocat dinamic cu O(logVAL_MAX) per update sau query
Interpretare geometrica
Sa ne intoarcem la formula de recurenta de mai devreme:
Putem observa ca ![max(sa[N] - sa[T], sb[N] - sb[T]) = max(|sa[N] - sa[T]|, |sb[N] - sb[T]|)](http://www.infoarena.ro/static/images/latex/14050659a8f9aeafa24bed9752c23c77_3.5pt.gif "max(sa[N] - sa[T], sb[N] - sb[T]) = max(|sa[N] - sa[T]|, |sb[N] - sb[T]|)") . Aceasta formula reprezinta distanta Cebisev intre punctele {sa[N], sb[N]} si {sa[T], sb[T]}. Astfel, putem sa consideram in plan punctele {sa[N], sb[N]}.
. Aceasta formula reprezinta distanta Cebisev intre punctele {sa[N], sb[N]} si {sa[T], sb[T]}. Astfel, putem sa consideram in plan punctele {sa[N], sb[N]}.
Sa presupunem ca pentru un anumit K, vrem sa calculam dp[K][6] pe desenul de mai sus. Putem observa ca in semiplanul marcat cu rosu, distanta Cebisev intre P6 si orice alt punct din in planul rosu va fi diferenta absoluta pe proiectiile celor doua puncte pe axa Oy, iar in cele din planul marcat cu verde va fi diferenta absoluta pe proiectiile celor doua puncte pe axa Ox. O sa tinem minte pentru fiecare diagonala paralela cu diagonala x = y care este dp[K][T] - sa[T] minim, respectiv dp[K][T] - sb[T]. Pentru un punct {x, y}, toate diagonalele se vor imparti in doua clase: cele de deasupra diagonalei din {x, y} si cele de sub diagonala. Pentru cele de deasupra diagonale (de exemplu pe cele din aria verde pentru punctul P6), optimul va fi minimul de pe fiecare diagonala de deasupra la care adunam x. Pentru cele de sub diagonala (cele din aria rosie pentru punctul P6), optimul va fi minimul de pe fiecare diagonala de sub la care adunam y.
Putem numerota diagonalele in mai multe feluri, unul din acestea fiind urmatorul: punctul {x, y} apartine diagonalei d = x - y. Astfel, punctele de sub o diagonala d vor diagonalele d + 1, d + 2, ..., iar cele de deasupra diagonalei d vor fi d - 1, d - 2, ....
Inlocuind modificarile noastre cu datele din solutia precedenta, vom obtine urmatoarele lucruri:
- Avem punctele {sa[N], sb[N]}
- Un punct {sa[N], sb[N]} apartine diagonalei d = sa[N] - sb[N]
- Un punct {sa[T], sb[T]} este deasupra diagonalei d = sa[N] - sb[N] <=> sa[T] - sb[T] <= sa[N] - sb[N]
- Pentru fiecare diagonala tinem minte dp[K][N] - sa[N] minim, respectiv dp[K][N] - sb[N] minim.
Putem observa echivalenta intre cele doua solutii, punctele 2 si 3 reprezentand conditia din formula de recurenta de mai sus, iar minimele pe care le tinem pentru fiecare diagonala d, vor fi defapt besta[d] si bestb[d], folosind notatiile din solutia precedenta.
Solutia problemei Dupadealuri
Multumim lui 
Solutie O(N^3) – 20 de puncte
Pentru orice subsecventa din sir, eliminam acea subsecventa si apoi verificam daca ce ne-a ramas este un palindrom. Complexitate ") .
.
Solutie O(N^2) – 40 de puncte

Orice palindrom posibil va arata ca in imaginea de mai sus, cu secventele  si
si  (posibil vide) de lungime egala si simetrice si cu palindromul P. Prin urmare o solutie ar fi sa mergem cu un iterator l de la 0 la n/2 care sa ne dea lungimea si , verificand ca prefixul rescpectiv sufixul de lungime l sunt simetrice. Pentru fiecare l valid putem gasi toate palindroamele P care se invechineaza cu l in
(posibil vide) de lungime egala si simetrice si cu palindromul P. Prin urmare o solutie ar fi sa mergem cu un iterator l de la 0 la n/2 care sa ne dea lungimea si , verificand ca prefixul rescpectiv sufixul de lungime l sunt simetrice. Pentru fiecare l valid putem gasi toate palindroamele P care se invechineaza cu l in ") pentru fiecare l cu hashing sau cu Algoritmul lui Manacher. Complexitate totala
pentru fiecare l cu hashing sau cu Algoritmul lui Manacher. Complexitate totala ") .
.
Solutie O(N) – 100 de puncte.
Solutia de e foarte similara cu cea de numai ca incercand pentru fiecare l sa aflam rezultatul in ") . Facand mai intai Manacher pe tot sirul putem afla pentru fiecare punct i palindromul maximal din i ($nota:$ la Manacher i nu e neaparat un numar natural datorita palindroamelor de lungime para).
. Facand mai intai Manacher pe tot sirul putem afla pentru fiecare punct i palindromul maximal din i ($nota:$ la Manacher i nu e neaparat un numar natural datorita palindroamelor de lungime para).
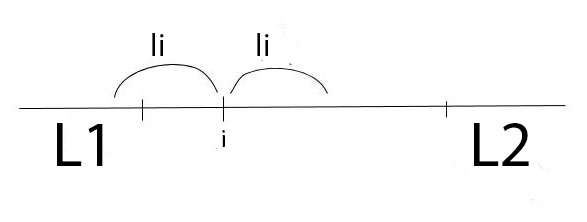
Dupa cum se vede mai jos  si
si  daca si numai daca va exista un palindrom cu centrul in i care sa se invechineze cu . Dat fiind ca lungimile lui , care se invechineaza cu un palindrom cu centrul in i, sunt consecutive si stiute (
daca si numai daca va exista un palindrom cu centrul in i care sa se invechineze cu . Dat fiind ca lungimile lui , care se invechineaza cu un palindrom cu centrul in i, sunt consecutive si stiute ( …
… unde
unde  este distanta de la i la capatul palindromului maximal) putem face Mo pentru a afla raspunsul final.
este distanta de la i la capatul palindromului maximal) putem face Mo pentru a afla raspunsul final.
Nota de final: Aveti grija pentru fiecare i la cine faceti suma partiala in functie de care dintre si va invechina palindromul cu centrul in i.
