Revizia anterioară Revizia următoare
Heap-uri
(Categoria Structuri de date, Autor Catalin Francu)
Sa pornim de la o problema interesanta mai mult din punct de vedere teoretic:
Enunt
Un vector se numeste k-sortat daca orice element al sau se gaseste la o distanta cel mult egala cu k de locul care i s-ar cuveni in vectorul sortat. Iata un exemplu de vector 2-sortat cu 5 elemente:

Se observa ca elementele 4 si 6 se afla la doua pozitii distanta de locul lor in vectorul sortat, elementele 2 si 7 se afla la o pozitie distanta, iar elementul 10 se afla chiar pe pozitia corecta. Distanta maxima este 2, deci vectorul V este 2-sortat. Desigur, un vector k-sortat este in acelasi timp si un vector (k+1)-sortat, si un vector (k+2)-sortat etc., deoarece, daca orice element se afla la o distanta mai mica sau egala cu k de locul potrivit, cu atat mai mult el se va afla la o distanta mai mica sau egala cu k+1, k+2 etc. In continuare, cand vom spune ca vectorul este k-sortat, ne vom referi la cel mai mic k pentru care afirmatia este adevarata. Prin urmare, un vector cu N elemente poate fi N-1 sortat in cazul cel mai defavorabil. Mai facem precizarea ca un vector 0-sortat este un vector sortat in intelesul obisnuit al cuvantului, deoarece fiecare element se afla la o distanta egala cu 0 de locul sau.
Problema este: dandu-se un vector k-sortat cu N elemente numere intregi, se cere sa-l sortam intr-un timp mai bun decat O(N*log N).
Date de intrare
Fisierul input.txt contine pe prima linie valorile lui N si K , despartite printr-un spatiu. Pe a doua linie se dau cele N elemente ale vectorului, despartite prin spatii.
Date de iesire
In fisierul output.txt se vor tipari pe o singura linie elementele vectorului sortat, separate prin spatii.
Exemplu:
| input.txt | output.txt |
|---|---|
| 5 6 2 7 4 10 | 2 4 6 7 10 |
Restrictii si precizari
- 2 ≤ K < N
- N ≤ 10000
- Timp de implementare: 45 minute.
- Timp de rulare: 5 secunde. ????
- Complexitate ceruta: O(N*log N).
Rezolvare
Vom incepe prin a defini notiunea de HEAP. Un heap (engl. gramada) este un vector care poate fi privit si ca un arbore binar, asa cum se vede in figura de mai jos:
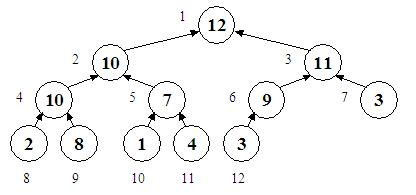
Langa fiecare nod din arbore se afla cate un numar, reprezentand pozitia in vector pe care ar avea-o nodul respectiv. Pentru cazul considerat, vectorul echivalent ar fi:

Se observa ca nodurile sunt parcurse de la stanga la dreapta si de sus in jos. O proprietate necesara pentru ca un arbore binar sa se poata numi heap este ca toate nivelele sa fie complete, cu exceptia ultimului, care se completeaza incepand de la stanga si continuand pana la un punct. De aici de ducem ca inaltimea unui heap cu N noduri este

(reamintim ca inaltimea unui arbore este adancimea maxima a unui nod, considerand radacina drept nodul de adancime 0). Reciproc, numarul de noduri ale unui heap de inaltime h este:

Tot din aceasta organizare mai putem deduce ca tatal unui nod k > 1 este nodul [k/2], iar fiii nodului k sunt nodurile 2k si 2k+1. Daca 2k = N, atunci nodul 2k+1 nu exista, iar nodul k are un singur fiu; daca 2k > N, atunci nodul k este frunza si nu are nici un fiu. Exemple: tatal nodului 5 este nodul 2, iar fiii sai sunt nodurile 10 si 11. Tatal nodului 6 este nodul 3, iar unicul sau fiu este nodul 12. Tatal nodului 9 este nodul 4, iar fii nu are, fiind frunza in heap.
Dar cea mai importanta proprietate a heap-ului, cea care il face util in operatiile de cautare, este aceea ca valoarea oricarui nod este mai mare sau egala cu valoarea oricarui fiu al sau. Dupa cum se vede mai sus, nodul 2 are valoarea 10, iar fiii sai - nodurile 4 si 5 - au valorile 10 si respectiv 7. Intrucat operatorul ≤ ??? este tranzitiv, putem trage concluzia ca un nod este mai mare sau egal decat oricare din nepotii sai si, generalizand, va rezulta ca orice nod este mai mare sau egal decat toate nodurile din subarborele a carui radacina este el.
Aceasta afirmatie nu decide in nici un fel intre valorile a doua noduri dispuse astfel incat nici unul nu este descendent al celuilalt. Cu alte cuvinte, nu inseamna ca orice nod de pe un nivel mic are valoare mai mare decat nodurile mai apropiate de frunze. Este cazul nodului 7, care are valoarea 3 si este mai mic decat nodul 9 de valoare 8, care este totusi asezat ma jos in heap. In orice caz, o prima concluzie care rezulta din aceasta proprietate este ca radacina are cea mai mare valoare din tot heap-ul.
Structura de heap permite efectuarea multor operatii intr-un timp foarte bun:
- Cautarea maximului in O(1)
- Crearea unei structuri de heap dintr-un vector oarecare in O(N)
- Eliminarea unui element in O(log N)
- Inserarea unui element in O(log N)
- Sortarea in O(N log N)
- Cautarea (singura care nu este prea eficienta) in O(N).
Desigur, toate aceste operatii se fac mentinand permanent structura de heap a arborelui, adica respectand modul de repartizare a nodurilor pe nivele si inaltarea elementelor de valoare mai mare. Este de la sine inteles ca datele nu se vor reprezenta in memorie in forma arborescenta, ci in cea vectoriala. Sa le analizam pe rand.
Cautarea maximului
Practic operatia aceasta nu are de facut decat sa intoarca valoarea primului element din vector:typedef int Heapi10001s;
void Max(Heap H, int N)
{
return Hi1s;
}