Revizia anterioară Revizia următoare
Heap-uri
 Acest articol a fost adăugat de Acest articol a fost adăugat de  Claudia Cardei •cyber şi Claudia Cardei •cyber şi  Silviu-Ionut Ganceanu •silviug Silviu-Ionut Ganceanu •silviugIntră aici dacă doreşti să scrii articole sau află cum te poţi implica în celelalte proiecte infoarena! |
(Categoria Structuri de date, Autor Catalin Francu, Versiunea originala preluata din cartea "Psihologia concursurilor de informatica")
- Continut
- Definirea notiunii de heap
- Structura de heap si metode ajutatoare
- Cautarea maximului
- Crearea unei structuri de heap dintr-un vector oarecare
- Eliminarea unui element, stiind pozitia lui in heap
- Inserarea unui element
- Sortarea unui vector
- Cautarea unui element
- Alternative STL
- Aplicatii
In acest articol vom prezenta structura de date numita heap, cum poate fi aceasta implementata, precum si alternative STL. Desi este putin probabil sa ajungeti sa implementati heap-urile de la "zero" daca stiti STL, consideram ca prezentarea acestora nu este de prisos. Aici atingem problema mai generala "de ce trebuie sa inteleg X (poate fi vorba de un algoritm, o structura de date, s.a.m.d.) daca il am deja implementat?". Iata cateva motive:
- va antreneaza mintea
- va veti putea descurca in situatii in care aveti nevoie de o structura de date asemanatoare, dar nu la fel
- veti fi utilizatori informati ai bibliotecii STL
- veti intelege cand este bine sa folositi o structura de date si cand nu
- veti avea avantajul de a sti precis de ce operatiile de baza au anumite complexitati
Acum ca avem o motivatie, sa studiem impreuna heap-urile.
Definirea notiunii de heap
Un heap (engl. gramada) este un vector care poate fi privit si ca un arbore binar, asa cum se vede in figura de mai jos:
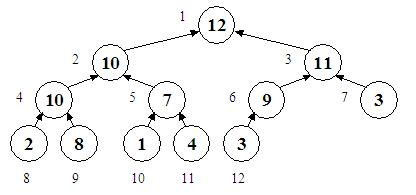
Langa fiecare nod din arbore se afla cate un numar, reprezentand pozitia in vector pe care ar avea-o nodul respectiv. Pentru cazul considerat, vectorul echivalent ar fi H = (12 10 11 10 7 9 3 2 8 1 4 3).
Se observa ca nodurile sunt parcurse de la stanga la dreapta si de sus in jos. O proprietate necesara pentru ca un arbore binar sa se poata numi heap este ca toate nivelurile sa fie complete, cu exceptia ultimului, care se completeaza incepand de la stanga si continuand pana la un anume punct. De aici deducem ca inaltimea unui heap cu N noduri este ![h=[\log_2 N]](http://www.infoarena.ro/static/images/latex/4e8209c9302fb36d8f99f478df58ef42_3.5pt.gif "h=[\log_2 N]") (reamintim ca inaltimea unui arbore este adancimea maxima a unui nod, considerand radacina drept nodul de adancime 0). Reciproc, numarul de noduri ale unui heap de inaltime h este
(reamintim ca inaltimea unui arbore este adancimea maxima a unui nod, considerand radacina drept nodul de adancime 0). Reciproc, numarul de noduri ale unui heap de inaltime h este ![N\in [2^h, 2^{h+1}-1]](http://www.infoarena.ro/static/images/latex/1593eb1ebc7b2592e0962ee9c74f5124_3.5pt.gif "N\in [2^h, 2^{h+1}-1]") .
.
Tot din aceasta organizare mai putem deduce ca tatal unui nod k > 1 este nodul [k/2], iar fiii nodului k sunt nodurile 2k si 2k+1. Daca 2k = N, atunci nodul 2k+1 nu exista, iar nodul k are un singur fiu; daca 2k > N, atunci nodul k este frunza si nu are niciun fiu. Exemple: tatal nodului 5 este nodul 2, iar fiii sai sunt nodurile 10 si 11. Tatal nodului 6 este nodul 3, iar unicul sau fiu este nodul 12. Tatal nodului 9 este nodul 4, iar fii nu are, fiind frunza in heap.
Dar cea mai importanta proprietate a heap-ului, cea care il face util in operatiile de aflarea a maximului, este aceea ca valoarea oricarui nod este mai mare sau egala cu valoarea oricarui fiu al sau. Dupa cum se vede mai sus, nodul 2 are valoarea 10, iar fiii sai - nodurile 4 si 5 - au valorile 10 si respectiv 7. Intrucat operatorul ≥ este tranzitiv, putem trage concluzia ca un nod este mai mare sau egal decat oricare din nepotii sai si, generalizand, va rezulta ca orice nod este mai mare sau egal decat toate nodurile din subarborele a carui radacina este.
Aceasta afirmatie nu decide in niciun fel intre valorile a doua noduri dispuse astfel incat niciunul nu este descendent al celuilalt. Cu alte cuvinte, nu inseamna ca orice nod de pe un nivel mic are valoare mai mare decat nodurile mai apropiate de frunze. Este cazul nodului 7, care are valoarea 3 si este mai mic decat nodul 9 de valoare 8, nod asezat totusi mai jos in heap. In orice caz, o prima concluzie care rezulta din aceasta proprietate este ca radacina are cea mai mare valoare din tot heap-ul.
Structura de heap permite efectuarea multor operatii intr-un timp foarte bun:
- Cautarea maximului in O(1)
- Crearea unei structuri de heap dintr-un vector oarecare in O(N)
- Eliminarea unui element in O(log N)
- Inserarea unui element in O(log N)
- Sortarea elementelor din heap in O(N log N)
Mentionam ca operatia de cautare a unui element are complexitatea O(N) dar, de obicei, heap-ul nu este folosit cand acest tip de operatii este frecvent.
Desigur, toate aceste operatii se fac mentinand permanent structura de heap a arborelui, adica respectand modul de repartizare a nodurilor pe niveluri si plasarea mai sus a elementelor de valoare mai mare. Este de la sine inteles ca datele nu se vor reprezenta in memorie in forma arborescenta, ci in cea vectoriala.
Precizam de asemenea ca heap-ul poate fi organizat si pe baza operatorului de ≤. In acest caz, in varful heap-ului vom avea minimul dintre elementele pastrate in heap. In functie de operatorul folosit, putem numi structura de date max-heap sau min-heap. In continuare vom prezenta operatiile intr-un max-heap, adaptarea lor pentru min-heap-uri fiind usoara.
Structura de heap si metode ajutatoare
In blocul de cod de mai jos prezentam cum se defineste un heap ca vector si cateva metode ajutatoare:
const int MAX_HEAP_SIZE = 16384;
typedef int Heap[MAX_HEAP_SIZE];
inline int father(int nod) {
return nod / 2;
}
inline int left_son(int nod) {
return nod * 2;
}
inline int right_son(int nod) {
return nod * 2 + 1;
}Cautarea maximului
Practic, operatia aceasta nu are de facut decat sa intoarca valoarea primului element din vector:inline int max(Heap H) {
return H[1];
}Crearea unei structuri de heap dintr-un vector oarecare
Pentru a discuta acest aspect, vom vorbi mai intai despre doua proceduri specifice heap-urilor, sift (engl. a cerne) si percolate (engl. a se infiltra). Sa presupunem ca un vector are o structura de heap, cu exceptia unui nod care este mai mic decat unul din fiii sai. Este cazul nodului 3 din figura de mai jos, care are o valoare mai mica decat fiii sai (nodurile 6 si 7):
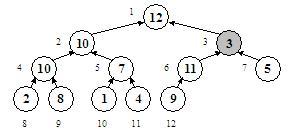
Ce e de facut? Desigur, nodul va trebui coborat in arbore, iar in locul lui vom aduce alt nod, mai exact unul dintre fiii sai. Intrebarea este: care din fiii sai? Daca vom aduce nodul 7 in locul lui, acesta fiind mai mic decat nodul 6, anomalia se va pastra. Trebuie deci sa schimbam nodul 3 cu nodul 6:
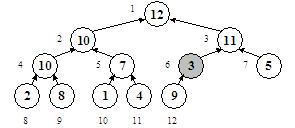
Problema nu este insa rezolvata, deoarece noul nod 6, proaspat "retrogradat", este inca mai mic decat fiul sau, nodul 12. De data aceasta avem un singur fiu, deci o singura optiune: schimbam nodul 6 cu nodul 12 si obtinem o structura de heap corecta:
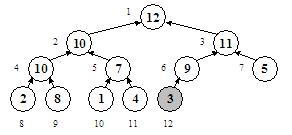
Procedura sift primeste ca parametri un heap H cu N noduri si un nod K si presupune ca ambii subarbori ai nodului K au structura de heap corecta. Misiunea ei este sa "cearna" nodul K pana la locul potrivit, interschimband mereu nodul cu cel mai mare fiu al sau pana cand nodul nu mai are fii (ajunge pe ultimul nivel in arbore) sau pana cand fiii sai au valori mai mici decat el.
void sift(Heap H, int N, int K) {
int son;
do {
son = 0;
// Alege un fiu mai mare ca tatal.
if (left_son(K) <= N) {
son = left_son(K);
if (right_son(K) <= N && H[right_son(K)] > H[left_son(K)]) {
son = right_son(K);
}
if (H[son] <= H[K]) {
son = 0;
}
}
if (son) {
swap(H[K], H[son]); // Functie STL ce interschimba H[K] cu H[son].
K = son;
}
} while (son);
}Procedura percolate se va ocupa tocmai de fenomenul invers. Sa presupunem ca un heap are o "defectiune" in sensul ca observam un nod care are o valoare mai mare decat tatal sau. Atunci, va trebui sa interschimbam cele doua noduri. Este cazul nodului 10 din figura care urmeaza. Deoarece fiul care trebuie urcat este mai mare ca tatal, care la randul lui (presupunand ca restul heap-ului e corect) este mai mare decat celalalt fiu al sau, rezulta ca dupa interschimbare fiul devenit tata este mai mare decat ambii sai fii. Trebuie totusi sa privim din nou in sus si sa continuam sa urcam nodul in arbore fie pana ajungem la radacina, fie pana ii gasim un tata mai mare ca el. Iata ce se intampla cu nodul 10:

void percolate(Heap H, int N, int K) {
int key = H[K];
while ((K > 1) && (key > H[father(K)])) {
H[K] = H[father(K)];
K = father(K);
}
H[K] = key;
}Acum ne putem ocupa efectiv de construirea unui heap. Am spus ca procedura sift presupune ca ambii fii ai nodului pentru care este ea apelata au structura de heap. Aceasta inseamna ca putem apela procedura sift pentru orice nod imediat superior nivelului frunzelor, deoarece frunzele sunt arbori cu un singur nod, si deci heap-uri corecte. Apeland procedura sift pentru toate nodurile de deasupra frunzelor, vom obtine deja o structura mai organizata, asigurandu-ne ca pe ultimele doua niveluri avem de-a face numai cu heap-uri. Apoi apelam aceeasi procedura pentru nodurile de pe al treilea nivel incepand de la frunze, apoi pentru cele de deasupra lor si asa mai departe pana ajungem la radacina. In acest moment, heap-ul este construit. Iata cum functioneaza algoritmul pentru un arbore total dezorganizat:
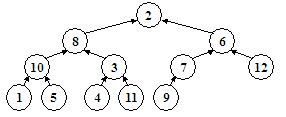
Nivelul frunzelor este organizat
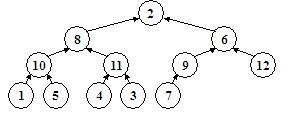
Ultimele doua niveluri sunt organizate
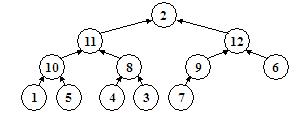
Ultimele trei niveluri sunt organizate
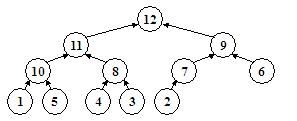
Structura de heap
void build_heap(Heap H, int N) {
for (int i = N / 2; i > 0; --i) {
sift(H, N, i);
}
}S-a apelat caderea incepand de la al N / 2 - lea nod, deoarece acesta este ultimul nod care mai are fii, restul cu indici mai mari fiind frunze. Sa calculam acum complexitatea acestui algoritm. Un calcul sumar ar putea spune: exista N noduri, fiecare din ele se "cerne" pe O(log N) niveluri, deci timpul de constructie a heap-ului este O(N log N). Totusi nu este asa. Presupunem ca ultimul nivel al heap-ului este plin. In acest caz, jumatate din noduri vor fi frunze si nu se vor cerne deloc. Un sfert din noduri se vor afla deasupra lor si se vor cerne cel mult un nivel. O optime din noduri se vor putea cerne cel mult doua niveluri, si asa mai departe, pana ajungem la radacina care se afla singura pe nivelul ei si va putea cadea maxim h niveluri (reamintim ca ). Rezulta ca timpul total de calcul este dat de formula ![O(\displaystyle {\sum_{k=1}^{[\log_2 N]} k} \times \frac{N}{2^{k+1}}) = O(N)](http://www.infoarena.ro/static/images/latex/06bc545b55cd213baf02fddee58dd50a_14.02782pt.gif "O(\displaystyle {\sum_{k=1}^{[\log_2 N]} k} \times \frac{N}{2^{k+1}}) = O(N)") . Demonstrarea egalitatii se poate face facand substitutia N = 2h si continuand calculele. Se va obtine tocmai complexitatea O(2h). Lasam aceasta verificare ca tema cititorului.
. Demonstrarea egalitatii se poate face facand substitutia N = 2h si continuand calculele. Se va obtine tocmai complexitatea O(2h). Lasam aceasta verificare ca tema cititorului.
Eliminarea unui element, stiind pozitia lui in heap
Daca eliminam un element din heap, trebuie numai sa refacem structura de heap. In locul nodului eliminat s-a creat un gol, pe care trebuie sa il umplem cu un alt nod. Care ar putea fi acela? Intrucat trebuie ca toate nivelurile sa fie complet ocupate, cu exceptia ultimului, care poate fi gol numai in partea sa dreapta, rezulta ca singurul nod pe care il putem pune in locul celui eliminat este ultimul din heap. O data ce l-am pus in gaura facuta, trebuie sa ne asiguram ca acest nod "de umplutura" nu strica proprietatea de heap. Deci vom verifica: daca nodul pus in loc este mai mare ca tatal sau, vom apela procedura percolate. Altfel vom apela procedura sift, in eventualitatea ca nodul este mai mic decat unul din fiii sai. Iata exemplul de mai jos:
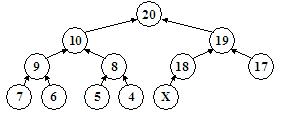
Sa presupunem ca vrem sa eliminam nodul de valoare 9, aducand in locul lui nodul de valoare X. Insa X poate fi orice numar mai mic sau egal cu 18. Spre exemplu, X poate fi 16, caz in care va trebui urcat deasupra nodului de valoare 10, sau poate fi 1, caz in care va trebui cernut pana la nivelul frunzelor. Deoarece caderea si urcarea se pot face pe cel mult [log N] niveluri, rezulta o complexitate a procedeului de O(log N).
void cut(Heap H, int& N, int K) {
H[K] = H[N];
--N;
if ((K > 1) && (H[K] > H[father(K)])) {
percolate(H, N, K);
} else {
sift(H, N, K);
}
}Inserarea unui element
Daca vrem sa inseram un nou element in heap, lucrurile sunt mult mai simple. Nu avem decat sa-l asezam pe a N + 1 - a pozitie in vector si apoi sa-l "promovam" pana la locul potrivit. Din nou, urcarea se poate face pe maxim [log N] niveluri, de unde complexitatea logaritmica.
void insert(Heap H, int& N, int key) {
H[++N] = key;
percolate(H, N, N);
}Sortarea unui vector (heapsort)
Acum ca am stabilit toate aceste lucruri, ideea algoritmului de sortare vine de la sine. Incepem prin a construi un heap. Apoi extragem maximul (adica varful heap-ului) si refacem heap-ul. Cele doua operatii luate la un loc dureaza O(1) + O(log N) = O(log N). Apoi extragem din nou maximul (care va fi al doilea element ca marime din vector) si refacem din nou heap-ul. Din nou, complexitatea operatiei compuse este O(log N). Daca facem acest lucru de N ori, vom obtine vectorul sortat intr-o complexitate de O(N log N).
Partea cea mai frumoasa a acestui algoritm este ca el nu foloseste deloc memorie suplimentara. Iata explicatia: cand heap-ul are N elemente, vom extrage maximul si il vom tine minte undeva in memorie. Pe de alta parte, in locul maximului (adica in radacina arborelui) trebuie adus ultimul element al vectorului, adica H[N]. Dupa aceasta operatie, heap-ul va avea N - 1 noduri, al N-lea ramanand liber. Ce alt loc mai inspirat decat acest al N-lea nod ne-am putea dori pentru a stoca maximul? Practic, am interschimbat radacina, adica pe H[1] cu H[N]. Acelasi lucru se face la fiecare pas, tinand cont de micsorarea permanenta a heap-ului.
void heapsort(Heap H, int N) {
build_heap(H, N);
// Sorteaza vectorul.
for (int i = N; i >= 2; --i) {
swap(H[1], H[i]);
sift(H, i - 1, 1);
}
}Cautarea unui element
Aceasta operatie este singura care nu poate fi optimizata (in sensul reducerii complexitatii sub O(N)). Aceasta deoarece putem fi siguri ca un nod mai mic este descendentul unuia mai mare, dar nu putem sti daca se afla in subarborele stang sau drept; din aceasta cauza, nu putem face o cautare binara. Totusi, o oarecare imbunatatire se poate aduce fata de cautarea secventiala. Daca radacina unui subarbore este mai mica decat valoarea cautata de noi, cu atat mai mult putem fi convinsi ca descendentii radacinii vor fi si ei mai mici, deci putem sa renuntam la a cauta acea valoare in tot subarborele. In felul acesta, se poate intampla ca bucati mari din heap sa nu mai fie explorate inutil. Pe cazul cel mai defavorabil, insa, parcurgerea intregului heap este necesara. Lasam scrierea unei proceduri de cautare pe seama cititorului.
Alternative STL
Desi nu sunt greu de implementat, avem vesti bune pentru programatorii in C++: heap-urile sunt deja implementate in STL. Containerul se numeste priority_queue si implementeaza toate operatiile prezentate, mai putin operatiile de cautare a unei valori si de stergere a unui nod. Aceste doua operatii sunt destul de atipice pentru o coada de prioritati si in general nu sunt asociate cu aceasta structura de date in cartile de algoritmi.
Totusi, in unele aplicatii avem nevoie de o structura de date care suporta toate operatiile amintite in timp cel mult logaritmic (inclusiv stergerea si cautarea unei valori). Aceasta structura exista deja in STL: set-urile. Acestea sunt de fapt multimi mentinute ca arbori binari echilibrati. Singurele dezavantaje sunt ca de obicei merg mai incet decat cozile de prioritate si folosesc mai multa memorie.
Daca nu sunteti familiari cu aceste structuri de date, va recomandam sa cititi paginile lor de documentatie: priority_queue, set si multiset. Daca nu intelegeti totul de la inceput (pentru ca nu stiti clase si template-uri in C++), uitati-va pe exemple si pe lista de functii membre si invatati cum se folosesc.
In continuare vom ilustra cum putem implementa operatiile de extragere a maximului, extragere a minimului, inserare, stergere si cautare folosind un multiset. Vom folosi un multiset pentru ca toate copiile unui numar vor fi pastrate daca el va fi inserat de mai multe ori (spre deosebire de set, care il va pastra o singura data). Va recomandam cu caldura sa copiati codul pe calculatorul vostru si sa experimentati cu el pentru a vedea ce afiseaza si a intelege ce se intampla.
#include <set>
using namespace std;
int main() {
multiset <int> my_set;
my_set.insert(1); // Insereaza o valoare.
my_set.insert(1);
if (my_set.find(1) != my_set.end()) { // Cauta o valoare.
printf("Am gasit 1 in set!\n");
} else {
printf("1 nu se afla set!\n");
}
// Sterge o valoare din set. Daca aceasta se afla de
// mai multe ori in set, este stearsa numai o copie.
my_set.erase(my_set.find(1));
printf("Exista %d elemente in set\n", my_set.size());
my_set.insert(1);
my_set.insert(1);
// Sterge o valoare din set. Daca aceasta se afla de
// mai multe ori in set, sunt sterse toate copiile.
my_set.erase(1);
printf("Exista %d elemente in set\n", my_set.size());
my_set.insert(1);
my_set.insert(-3);
my_set.insert(7);
// Valoarea minima.
multiset <int> :: iterator it = my_set.begin();
printf("Valoarea cea mai mica din set este %d\n", *it);
// Valoarea maxima.
it = my_set.end();
--it;
printf("Valoarea cea mai mare din set este %d\n", *it);
return 0;
}Aplicatii
- Dijkstra cu heap-uri
- Magnetic storms
- Manager
- Supermarket
- Sea - Baraj ONI 2004 (Autor: Radu Berinde)
- Interclasati K vectori sortati. (Sugestie: complexitatea dorita este O(N * log K), unde N este lungimea sirului rezultat prin interclasare)
- Determinati cele mai mici K elemente dintr-un sir cu N elemente cand dispuneti de memorie mult mai putina ca O(N). (K este mult mai mic decat N)
